

Freed from the tyranny of syntax
Freed from the tyranny of syntax
95% of lines of code will be written by AI within 3 years

Humans weren’t meant to code. Our evolutionary history includes zero generations of software engineers. This is why software engineers are so rare, why the desire for the average person to become a software engineer is so low despite the economic incentives, and why there is little to no social cachet attached to being a software engineer, compared to, say, a basketball player or a doctor.
Instead, humans who love to code do so because of the instinctive draw of power — the unbounded power of general computation — the ability to create anything you can imagine, with just a computer and your mind. If it were possible to harness the power of general computation without writing code, nearly everyone would choose to do so.
Indeed, what would a world without code look like? A world where the power of general computation was made available to everyone, without learning the syntax and semantics of computer languages?
How far off are AI Software Engineers?
Despite its incredible cognitive powers, GPT-4 hasn’t made much of a direct economic impact yet. Its primary miracle — conjuring up any desired piece of text instantly — is one that Google and the internet had already mastered decades ago.
Intuitively, though, there’s a deeper potential. GPT-4 is human or super-human level at a broad range of complex cognitive tasks. It has sound reasoning and a knowledge of language and the world that is unmatched by any single human intellect.
So what is holding it back?
Task-specific competency
Raw GPT-4 is good at one thing: producing plausible sequences of tokens, the thing it was trained to do. It is, without question, the very best to ever exist at this task. However, plausible token sequences are not particularly economically valuable on their own. GPT-4 can’t write the best sales email, successfully litigate a case, or write complex software. It can produce plausible-sounding sequences of tokens related to those tasks but lacks the innate training to actually complete them successfully. It’s the world’s greatest bullsh*tter but lacks actual task-specific competency or the generic ability to learn such competency.
Of course, the version of GPT-4 that we interact with (versus the raw pretrained GPT-4) has been trained for a specific task: producing sequences of tokens that human labelers thought were helpful, accurate, and appropriate. And it now works very well for this task — you can ask ChatGPT nearly any possible question about any possible topic and get a helpful, accurate, and appropriate response.
This raises the question: if you can teach GPT-4 to be a helpful oracle, what else can you teach it to do? And why hasn’t OpenAI taught it to do something more economically useful?
For one, it’s likely OpenAI is just too busy building the next version of GPT. Rumors are that GPT-5 will be another significant leap forward. Why waste time optimizing GPT-3 or 4 for a specific task when you know there is much more juice to get out of just making bigger and better mega-models.
Second, most economically valuable tasks have a more complex interface than just text input and output. You need to at least interact with a web browser, if not the physical world and other people.
Third, it’s hard to train task competency. For complex tasks, it’s possible you need millions of examples of doing a task well, across a broad range of the relevant state space, for an LLM to become competent.
So, when OpenAI or competitors do get around to training task-specific models, they will surely choose a task that:
is primarily text based,
has sufficient training examples that already exist, or can be cheaply generated or simulated,
is economically valuable.
Is there a task that fits all three of these criteria? Maybe one that, in turn, could even help you generate better AI itself?
The most expensive text in the world, token for token
Software development is an obvious target, not least because its sitting right there in front of the AI engineers themselves — engineers have always loved to scratch their own itch — but also because the training set already exists, the interface is text only, and the economic opportunity is enormous — software can cost $5-50 per line of code, all in. GPT-4 costs $0.0002 for that same line. That’s a solid 99.9999% margin on a trillion dollar occupation.
Why haven’t AI companies tackled it already?
Because software engineering is hard!
GPT-4, without any task-specific training, is a competent coder. For any self-contained, small-ish problem GPT-4 will output a correct and complete script, most of the time. On simple coding benchmarks, like HumanEval, it will get two-thirds of the questions correct out of the box, and up to 95% with iterated prompting techniques.
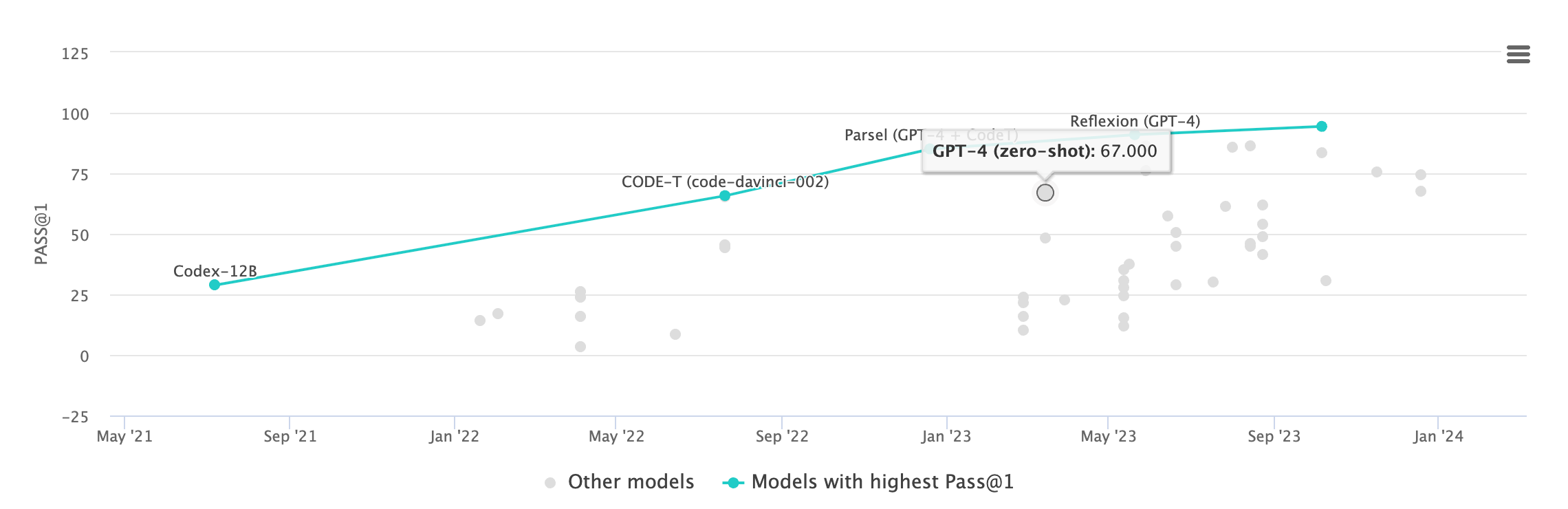
GPT-4 seems to have already solved some (decidedly hard) aspects of software development:
Complex abstract reasoning — GPT-4 has an astonishingly high level of logical reasoning for a next-token prediction machine. Its 90th percentile on the LSAT attests to this. It’s not perfect but very above average for a human.
Language and library knowledge — GPT-4 has nearly complete knowledge of all of the top programming languages as well as their popular libraries and apis.
General CS and software engineering know-how — It is fluent in data structures, algorithms, programming paradigms, and produces syntactically and semantically correct programs by default.
On the other hand, it has some glaring deficiencies:
No ability to learn and retain new knowledge — in this case specifically no ability to learn a new codebase or business domain and retain it across contexts.
Too little working memory — it can’t hold in its mind and reason about an entire real-world codebase and domain, or even a substantial portion of it. GPT-4’s new longer context variants are better here, but there’s no-free-lunch in terms of quality vs quantity — the more you give it in context the more likely it is to miss something essential or lose its train of thought
No actual training on the process of producing functioning, efficient, maintainable software — GPT-4 was trained on billions of tokens of mature open source software, but was not given any explicit training on how to produce such software. As it is, it must do so token by token, on the first try, perfectly.
In the end, GPT-4 is useful in software development, but really only as an assistant to an existing engineer, not as a replacement thereof; cf. Github Copilot.
But …. how quickly will the above shortcomings be overcome? Let’s look at each in turn.
1. Ability to learn and retain new knowledge
This one seems farthest off; none of the large model developers have mentioned such capabilities are coming. Fine tuning, as it exists today from the main model companies, is good for adjusting the output superficially (“style, tone, and format”), but not for incorporating new knowledge into the model’s reasoning. It’s possible new mixtures of experts architectures will allow for cheaper knowledge augmentation, but that has not been proven out commercially yet. Short-term, it’s likely the solution to this problem is to ignore it and hope the solution lies in solving the next shortcoming…
2. More working memory
This one seems likely to fall quickly to a version of Moore’s Law. Each successive model generation will grow in its working memory. A natural way we might think about the working memory of a model is its context length, but this belies the true “native” working memory of the model — you can extend the context length indefinitely but there’s still only so much the model can attend to at once. If every token of the long context is important, something will get lost. The true working memory of a model depends on the model architecture and specific dimensions; one simple measure is the query-key dimension of the transformer layers — this determines the set of orthogonal concepts the model can attend to.
There’s a natural limit to model sizes based on how many parameters can fit in GPU memory; as GPUs scale, this limit will scale. At the same time, mixtures of experts means you get more focused performance for the specific token at hand without sacrificing general intelligence or knowledge, giving more oomph out of the same working memory. Between Nvidia’s yearly design cadence, competitors’ offerings, and algorithmic improvements, we should expect to continue to see rapid increases in working memory for LLMs.
It’s quite possible that GPT-5, paired with smart context retrieval, will give us enough working memory already to reason about a large enough chunk of a real-world codebase and business domain that we don’t need to solve the “knowledge augmentation” problem above. It’s also possible we will have to wait a few more GPU generations.
3. Process training
Producing working code is an iterative process done over months and years and millions of human brain cycles. We should expect AI to work similarly. But current LLMs are trained to do one-off token completion, and nothing else. There is an endless list of prompting strategies (chain-of-thought, tree-of-thought, stepping-back) to overcome this limitation, but all still rely on the same underlying model that has no inherent motivation to produce great software.
Folks have attempted to overcome this by generating synthetic step-by-step datasets and fine-tuning models with process supervision — giving models feedback on not just the final output, but on the steps taken to get to it. This has shown good results; the question is then how to acquire LLM-scale datasets of high-quality process data.
Luckily, such a dataset exists, publicly, for free. In some sense, software Engineers have left a trail to their own demise: every Github pull request is a supervised training example of how to improve a codebase. Instead of training an LLM to output perfect code token by token on the first try, instead AI companies will train an LLM to take the codebase and PR title and description as input context and generate the PR patch as output, token by token. Such fine-tuning is possible today, and AI companies are already working on this, or preparing to. Up until now, context lengths have just been too small for this to really have any chance of working on real-world codebases — you need a lot of the codebase in context to be able to generate a useful and correct PR. There will likely need to be some innovation for bringing in context, where simple RAG will not be sufficient and you will need end-to-end back-propped retrieval systems built specifically for codebases. But this is a problem space that’s already been cracked many times.
The reality is that all three of these shortcomings are likely to fall with the advent of larger working memories in LLMs, which could come as soon as this year. Another six months or so after that to add software-specific training, and we could see AI software engineers arriving as soon as next year. They won’t be perfect, or even that good, but neither are a lot of human engineers (your author included) and they might make up for it in cost and willingness to take orders.
That is just the start though.
A million programmer lives
Passive training on open-source PRs is a nice way to bootstrap a decent AI software engineer. Again, it will be far from perfect, but I wouldn’t bet against it having a large economic impact without any further development.
The real gains, though, happen once we realize that a lot of software engineering scenarios and outcomes can be simulated and self-evaluated efficiently by this very same system. Once it gets to a certain level of competency it can self learn, AlphaZero style. The basic idea is to generate a synthetic training code example for the model and then evaluate the quality and correctness of its output. What that looks like exactly and how hard it is to simulate depends on the type of software development, but here are some quick possibilities:
Static frontend development - easy to simulate
Training task generation: Auto-generated screenshots of existing websites, recreate in code
Evaluation: Visual diff or GPT-4V soft eval; code quality eval
Bug / security hunting - easy/medium to simulate
Training task generation: AI-introduced bug in existing codebase that causes a test to fail
Evaluation: All tests pass again
Backend api - hard to simulate
Training task generation: AI-generated requirements and test suites
Evaluation: Test suite pass rate
Dynamic frontend - hardest to simulate?
Training task generation: Feature extension on existing application
Evaluation: AI-driven headless browser interaction producing correct end state
Software that involves end-user interaction will be most expensive to simulate and train against — you may need to co-develop a user-interaction AI that can click and scroll and type.
For static sites and backend APIs though, self-generation and evaluation should be more straightforward. The techniques above are just some starting ideas — the point is that training example generation is simple for a purely digital, text-only task like software engineering. This is in contrast to, say, legal work (another high dollar-per-token task!) that would require simulating complex human scenarios and interactions in order to self-improve on, a much harder task.
If the LLM can live a million programmer lives hunting bugs, passing tests, and building software that meets objectives, how will humans compete?
The very nature of software engineering
LLMs won’t do ground breaking research or engineer and architect large systems. They won’t interface with product managers and tech leads. They’ll miss bigger business context. They’ll fail to empathize properly with end-users.
But they will start to eat more and more of the day-to-day line-writing efforts of the world’s developers, slowly at first, and then very suddenly nearly all of it. The very nature of what utilizing general computation looks like will change overnight.
If anyone can create and build with computers, what happens next? When youtube and cheap bandwidth and cameras made it possible for anyone to produce their own “tv”, everyone won. The big hollywood names lost, but only on a relative basis as individual creators and Google and Meta grew exponentially. What we got in return was an explosion of creativity and content. The same has happened as the cost of producing music has been reduced to near zero.
Software engineers will lose their economic leverage and possibly their jobs. But as the cost of producing software is greatly reduced, so too will the demand for it increase. People with the drive and desire and skill for creating useful applications will have even more leverage. This is what new technology gives us — even more leverage on our time and resources, and thus higher earnings and quality of life for the same amount of work.
What creations will we bring forth into the world once freed from the tyranny of syntax?
***
The way things look, we won’t have to wait long to find out. Larger working memory, longer contexts, dedicated training on open-source pull requests, and continual improvement with simulated self-learning will produce an AI capable of replacing a big portion of the software development process, and do so as soon as within the next 12 months. More likely it will be 2-4 years to bring all these pieces together and commercialize them at scale.